How to perform PITR in PostgreSQL specially in v12 where recovery.conf file is no more valid. This blog is all about the setup and recovery.
if some important data got deleted or some table lost which we want to recover - we can get it by performing PITR .
Steps to perform PITR in PG v12
========================
in PG conf file - archive_mode and archive_command GUC variable should be set

Start the server /create table with data -

There are 2 important folders - pg_wal which reside under data directory and archive_directory which we have created explicitly (under /tmp).
pg_wal folder contain all the data history records e.g insert/update/delete all records stored in the files but after a certain limits of these files -it started overriding . To make sure -we have preserve all the WAL files before it override - we archive it by archive_command =cp '%p /tmp/<location/%f' ..
This process can be called 'incremental backup'.
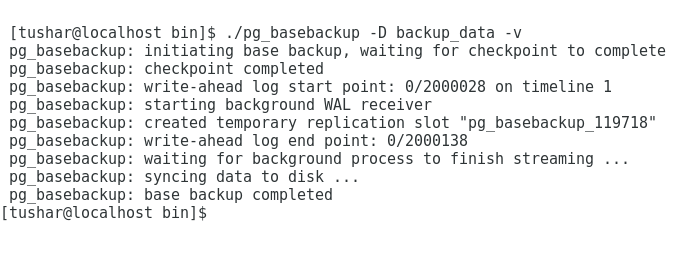
Perform pg_basebackup ( to perform online full backup )

Scenario is -
at X time- User has dropped all the rows = count is 0 rows
at Y time- User has inserted 50 rows =count is 50 rows
at Z time- User has inserted 1 lakh rows =count is 1 lakh 50 rows
We want to perform recovery at Y time where count is 50 rows.
at X time -
 at Y time -
at Y time -

at Z time -

Z time =2019-09-10 17:58:05
Now, Time to perform recovery till Y time
Stop the Server (./pg_ctl -D my_data stop -m i)
Go to folder - backup_data (full backup ,which we have taken earlier)
Open postgresql.conf file and add these below GUC parameters

Recovery is now (in v12) initialised by a file called 'recovery.signal' - empty file need to be create manually in data directory folder .

Start the server -

recovery.signal file has been automatically removed from data folder .
Connect to psql terminal and check the data

if some important data got deleted or some table lost which we want to recover - we can get it by performing PITR .
Steps to perform PITR in PG v12
========================
in PG conf file - archive_mode and archive_command GUC variable should be set
Make sure - /tmp/archive_directory directory exists on machine . /tmp is not a good location to store the WAL files.

There are 2 important folders - pg_wal which reside under data directory and archive_directory which we have created explicitly (under /tmp).
pg_wal folder contain all the data history records e.g insert/update/delete all records stored in the files but after a certain limits of these files -it started overriding . To make sure -we have preserve all the WAL files before it override - we archive it by archive_command =cp '%p /tmp/<location/%f' ..
This process can be called 'incremental backup'.
Perform pg_basebackup ( to perform online full backup )
Scenario is -
at X time- User has dropped all the rows = count is 0 rows
at Y time- User has inserted 50 rows =count is 50 rows
at Z time- User has inserted 1 lakh rows =count is 1 lakh 50 rows
We want to perform recovery at Y time where count is 50 rows.
at X time -


at Z time -

X time =2019-09-10 17:53:13
Y time =2019-09-10 17:55:48Z time =2019-09-10 17:58:05
Now, Time to perform recovery till Y time
Stop the Server (./pg_ctl -D my_data stop -m i)
Go to folder - backup_data (full backup ,which we have taken earlier)
Open postgresql.conf file and add these below GUC parameters

Recovery is now (in v12) initialised by a file called 'recovery.signal' - empty file need to be create manually in data directory folder .

Start the server -

recovery.signal file has been automatically removed from data folder .
Connect to psql terminal and check the data
Data has been recovered till Y point .
























{kind=link}