In this blog, we are going to see -
How to export data from PostgreSQL tables to CSV files and
How to import data from csv file into a PostgreSQL table.
I have created this table in PG -

Contents of CSV data file -

We can import CSV file into this 'my_table' table using copy command -
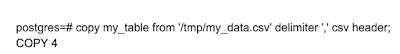
Table columns orders should be the same which is mentioned in CSV file or vice versa.
Header keyword is indicating CSV file contain header i.e columns name
Delimiter is used to indicate value is separated using ','
Data has been imported into PG table -

Similarly ,We can perform Export PG table data into CSV file using copy command -

my_export_data.csv is being created
 Instead of selecting all the columns , we can select any particular column as well ,in this example
Instead of selecting all the columns , we can select any particular column as well ,in this example
using only id column

my_export_data.csv is showing data of column 'id'

We can also specify condition if any particular data we are looking -for instance id=1

How to export data from PostgreSQL tables to CSV files and
How to import data from csv file into a PostgreSQL table.
I have created this table in PG -

Contents of CSV data file -

We can import CSV file into this 'my_table' table using copy command -

Table columns orders should be the same which is mentioned in CSV file or vice versa.
Header keyword is indicating CSV file contain header i.e columns name
Delimiter is used to indicate value is separated using ','
Data has been imported into PG table -

Similarly ,We can perform Export PG table data into CSV file using copy command -

my_export_data.csv is being created

using only id column

my_export_data.csv is showing data of column 'id'

We can also specify condition if any particular data we are looking -for instance id=1

More details can be found at - COPY command












































{kind=link}
{kind=link}
{kind=link}